Heart Disease Classifier
Using data science to make impactful decisions on medicine to benefit society
Using data science to make impactful decisions on medicine to benefit society
Heart disease is an extremely broad category. While there are several heart specific diseases such as heart rhythm problems (arrythmias) and congenital heart defects (ones people are born with), several can influence the entire cardiovascular system. This includes all the blood vessels that run throughout the body. In these blood vessels several other diseases, such as atherosclerosis (a plaque accumulation in the arteries) can occur. If the heart can’t pump blood properly, it will eventually cause functions in other parts of the body, especially the lungs and kidneys to be disrupted. This disruption may lead to swelling in the legs, shortness of breath and eventually heart failure. It's important to know how vital a properly functioning heart is, which only increases the imperativeness to prevent any heart disease by detecting the risk.

There are two main types of risk factors for any medical condition: Modifiable and Non-modifiable. Modifiable risk factors are based on a person’s life choices, such as diet and general lifestyle. Non-modifiable risk factors are based on factors out of an individual’s control, such as family medical history, sex, and age. Both can cause equal susceptibility to heart problems, but only modifiable risk factors can be prevented and taken care of.
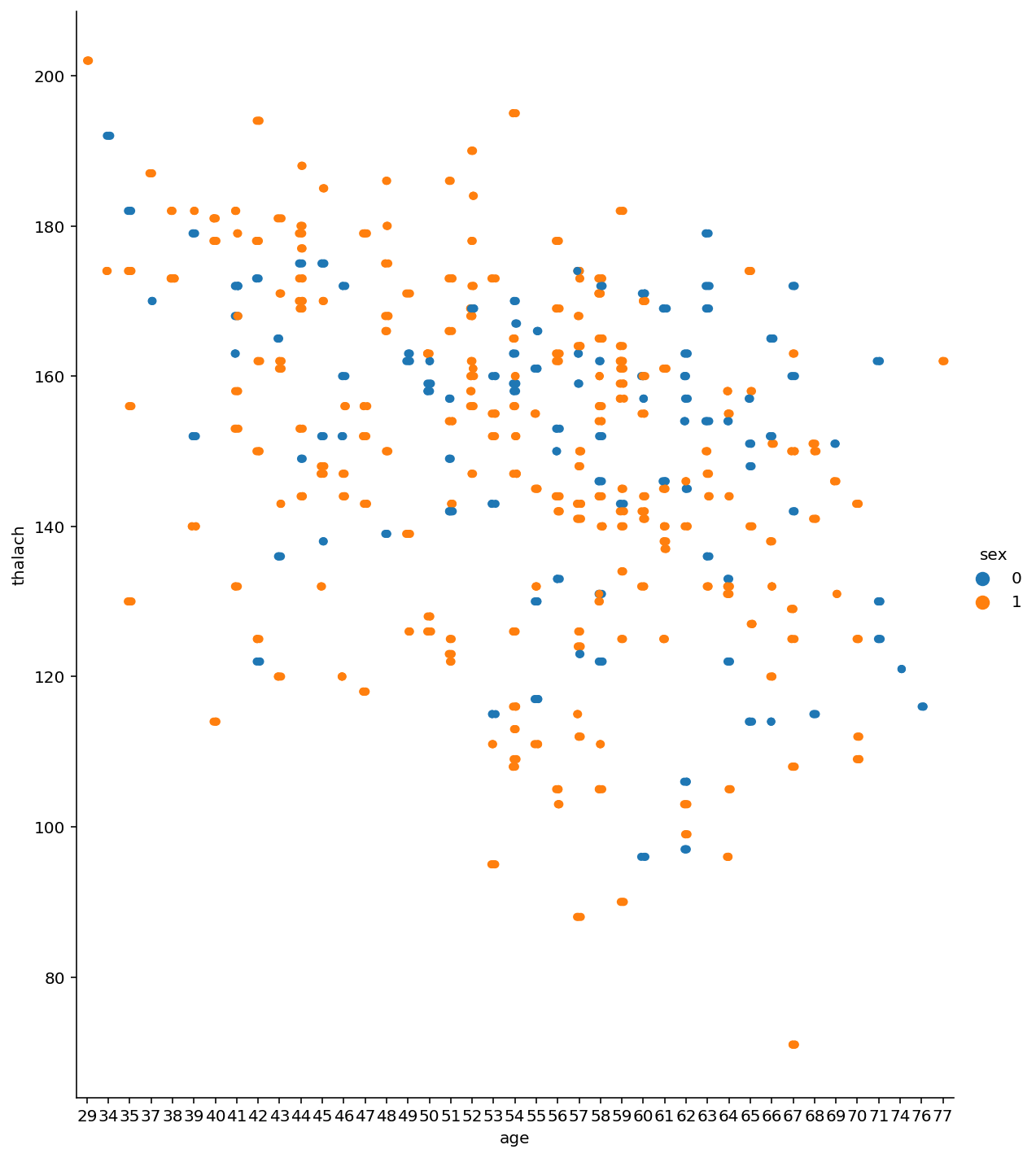
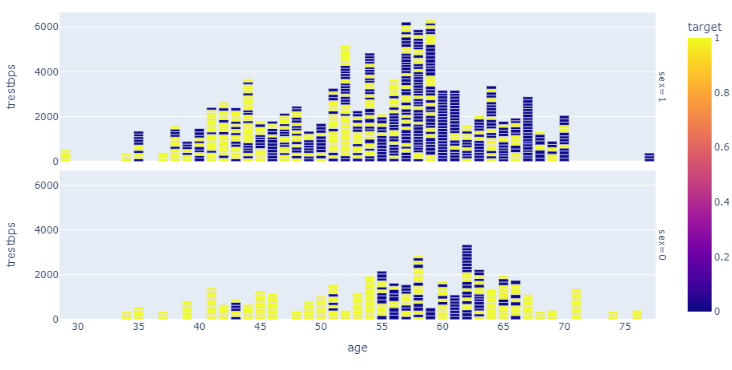
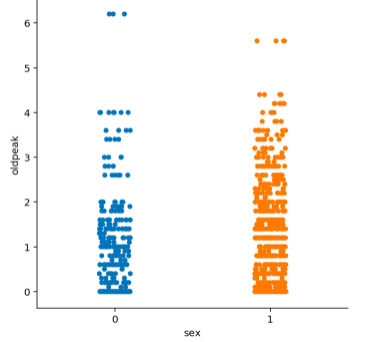
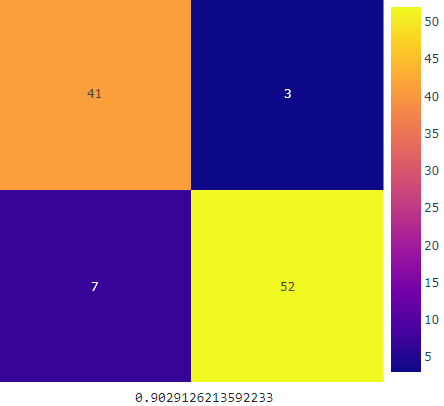
Our visualizations were made to help us better analyze our data. Here is what we found out:







Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset. This improves the quality of the training data for analytics and enables accurate decision-making.
For our dataset, we performed the steps below to get a cleaner dataset that would be more suitable for our machine learning models:

Machine learning is subfield of artificial intelligence that allows software applications to become more accurate at predicting outcomes without being explicitly programmed to do so. Machine learning algorithms use historical data as as input to predict new output values. The three types of machine learning includes supervised machine learning, unsupervised machine learning, and reinforcement learning. Supervised machine learning is when data is given to predict future outcomes. Unsupervised machine learning uses a machine algorithm from previous data to predict future outcomes. Reinforcement learning is output based on the state of the current input, then the next input depends on the previous input.

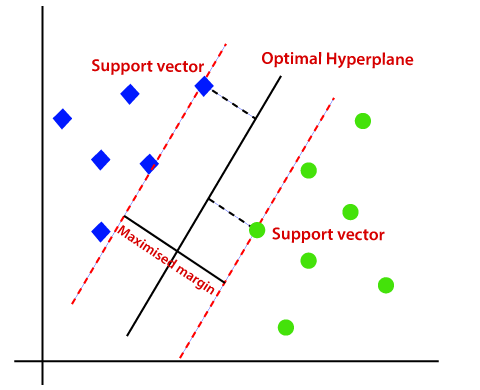
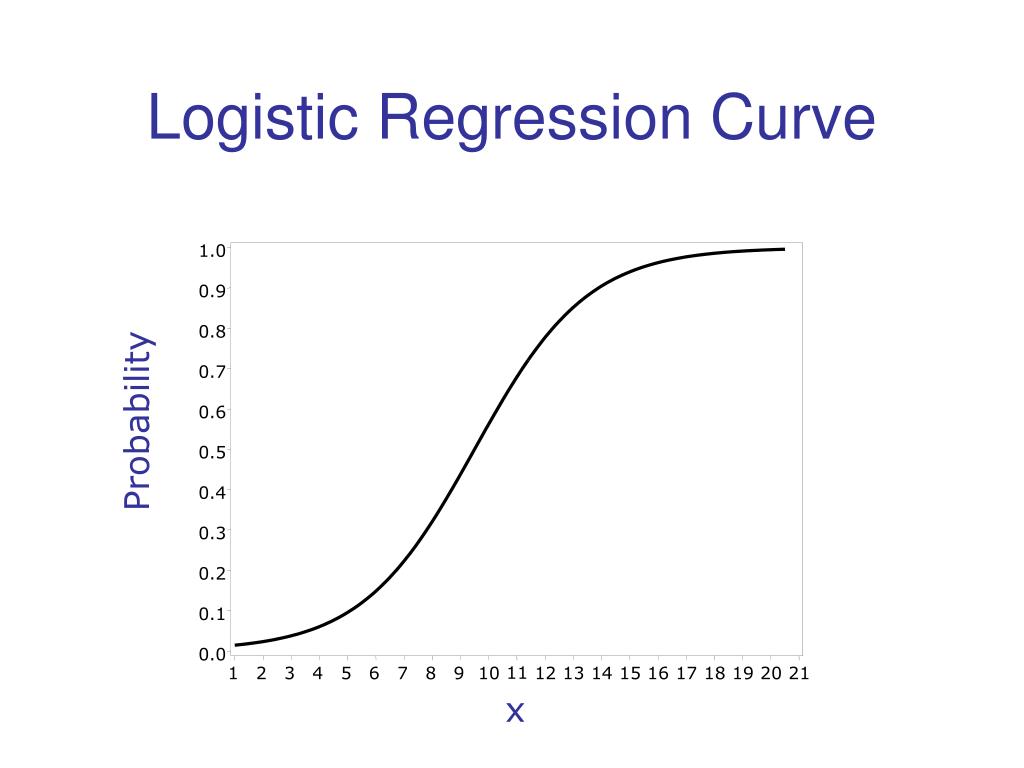

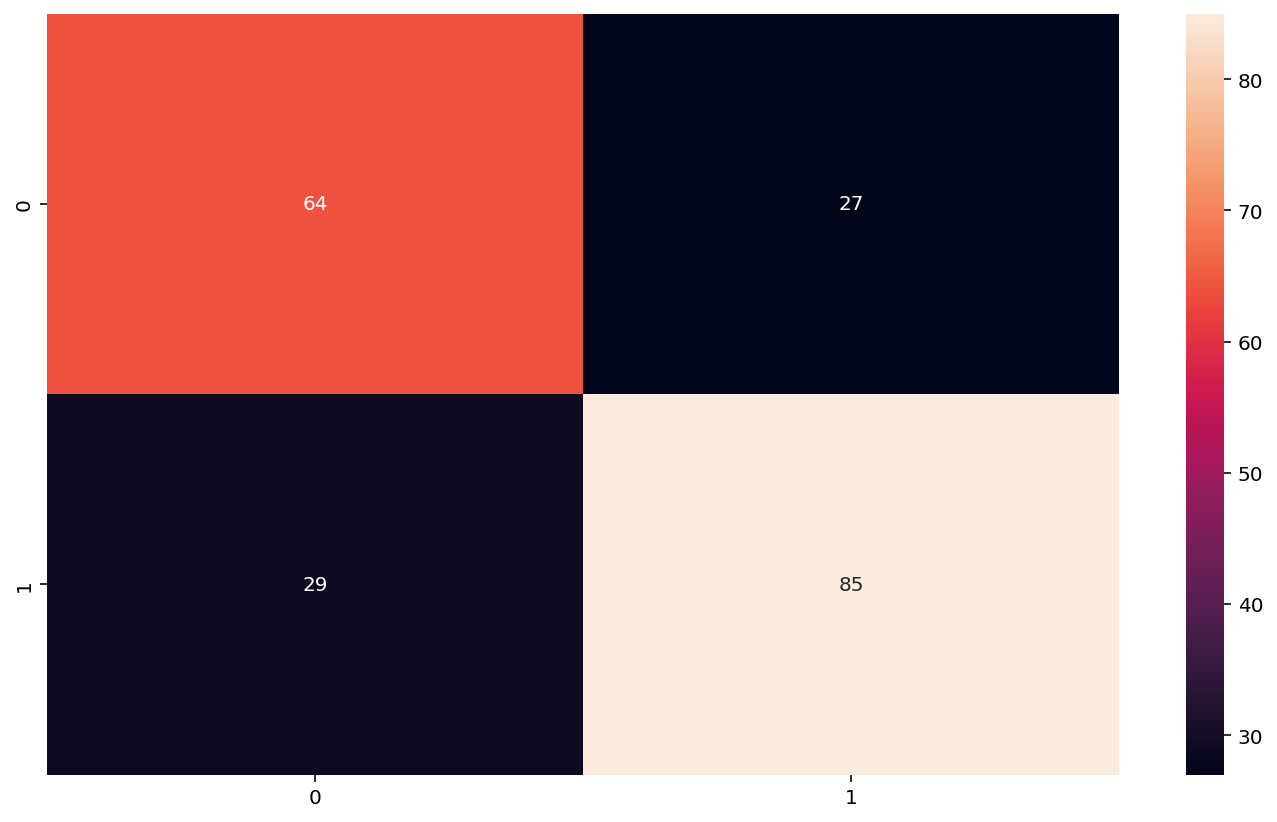
With the several different models we have coded, we can most likely assess with reliable accuracy a person’s risk for heart disease. While as of now the random forest model was most accurate, reaching 99% accuracy, we can continue to improve the other models to improve their accuracy rate as well. Additionally, we coped with a relatively small dataset and minimal prior coding experience, so in the future we can implement more AI and use this knowledge as a foundation to achieve greater results.