
K-NN is a supervised machine learning algorithm that predicts similarity between new data (x_test inputs) and available data (x_train, y_train inputs). The code import KNN from the SKLearn Library is as follows:
from sklearn.neighbors import KNeighborsClassifier as KNN
Why KNN?
K-NN can be used for regression and classification. In our case, we used K-NN to classify if a transaction was fraud or not (i.e. binary classification).

How?
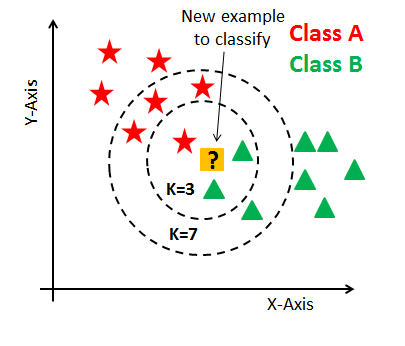
To simplify it into 2-D space, (since we have >2 features, hence a very complex plane) let’s say that we are predicting what an input should be classified/categorized as by taking the Euclidean distance* of every data point in the space.

*Keep in mind, there are many other distance metrics that can be used to find the K-Nearest Neighbor, but Euclidean distance was the simplest for us to implement.
With the closest data points from your input, we would take the closest K-Number of Neighbors (specified by you). Then, take a majority vote** of which category of points is seen more, and the input will be classified as that category.

** Good thing to note is that since it’s based on voting, you would want a tie-breaker in the case that there is an equal number of points for both categories.
If you want to learn more about KNN, and what makes KNN's implementation simple, click the link here:
K-Nearest Neighbors: Algorithm for MLOur KNN Experience
Data and Analysis
Through multiple trials, we found that the K-Nearest Neighbors algorithm was a highly accurate machine learning model that landed a 99.95% accuracy score, with a 0.94 precision, recall, and f1-score. Knowing this, you can see in our heat-map below that our model had 19,977 true positive predictions (top left), 7 true negative predictions (bottom right), and only 11 false negatives (bottom left) and 0 false positives (top right). Therefore, our model made only 11 mistakes; these mistakes would be the worst case scenario since it's better to have false alarms (false positive) rather than a fraud case being swept under the rug (false negative).

Hyper-parameter Tuning
N_Neighbors
N_neighbors is the specified number of data points closest to the new input that will be used to classify said input. This parameter
is of type 'int' and is defaulted to 5 neighbors.
Weights
Weights is the function that specifies how much each feature influences/affects our model's prediction based on distance. This parameter
is of type 'string' and is defaulted to 'uniform.'
Algorithm
The algorithm used to compute the nearest neighbors from the new input based on the specified distance metric. All of the algorithms
consist of:
-
ball_tree -
kd_tree -
brute -
auto
The algorithm hyper-parameter is defaulted to 'auto,' meaning the program will automatically choose the algorithm
appropriate for the values passed by the
fit
method.