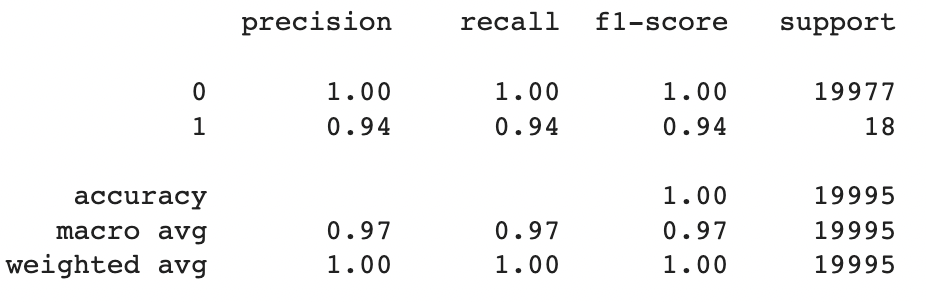
Random Forest creates decision trees on selected data, collects a prediction from each tree, and then selects the prediction with the most votes (occurrences) as the final prediction. This process is shown clearly in the image below.
Training the Model
We split our data 80-20 (train-test). From sklearn we imported the Random Forest Classifier and created a gaussian classifier where we tuned the hyperparameter, n_estimators (the number of trees you want to build before taking the maximum voting). We set the value of n_estimators to 2 because the accuracy remained the same when we had more than 2 n_estimators. We trained our model using the .fit() method from sklearn.
from sklearn.ensemble import RandomForestClassifier
Testing the Model/ Results
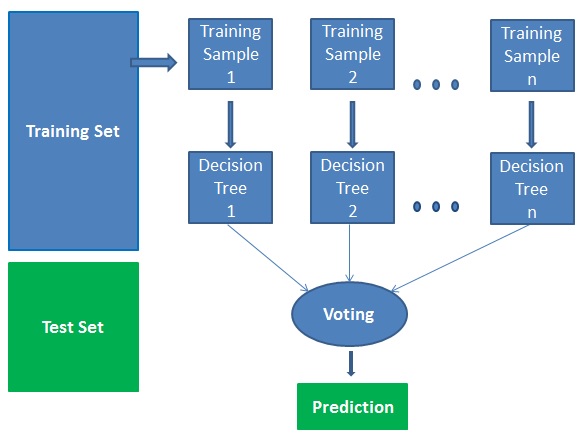
After training our model we checked the accuracy of our model by using metrics.accuracy_score from sklearn and we got an accuracy of 0.999899. To visualize the performance of our classification algorithm we made a confusion matrix. From our confusion matrix, we found out that from the predictions 19,976 True Positives, 1 False Positive, 17 True Negative, and 1 False Negatives.There were only 2 mistakes made by the model, which explains our high accuracy score. The classification report also reflects our high accuracy score.
metrics.accuracy_score=0.999899 metrics.roc_auc_score=0.972197
Confusion Matrix
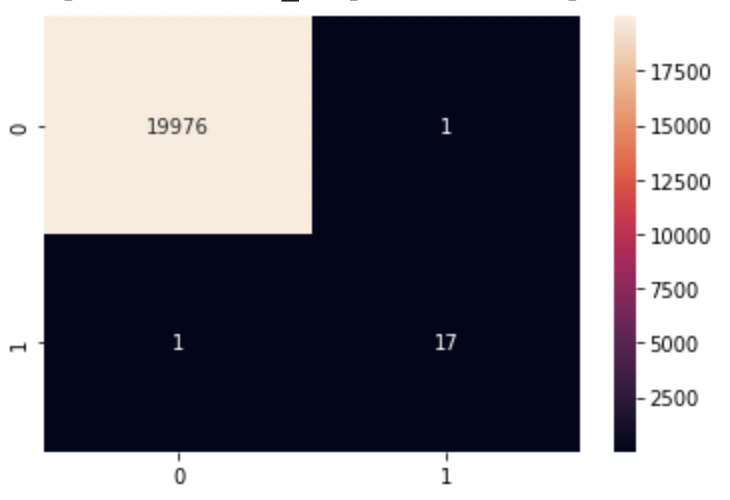
Classification Report